Tools
Every deliberation, whether in a lab or in the real world, can be described by a set of features such as the average age of the participants, the moral character of the topic, or the experience that the participants have with the problem they are discussing. We can think about these features as localizing a particular deliberation in a multidimensional space defined by these features. Deliberations that are similar in nature sit at similar points in the space, while those that are more distinct sit at a distance from one another.
In order to understand how to support a particular deliberation, we need to know where it sits in the space, and how we can use information collected from past experiments to make predictions about that point in the space.
The tools below are designed to help researchers collaborate to map that space.
A high-throughput virtual laboratory
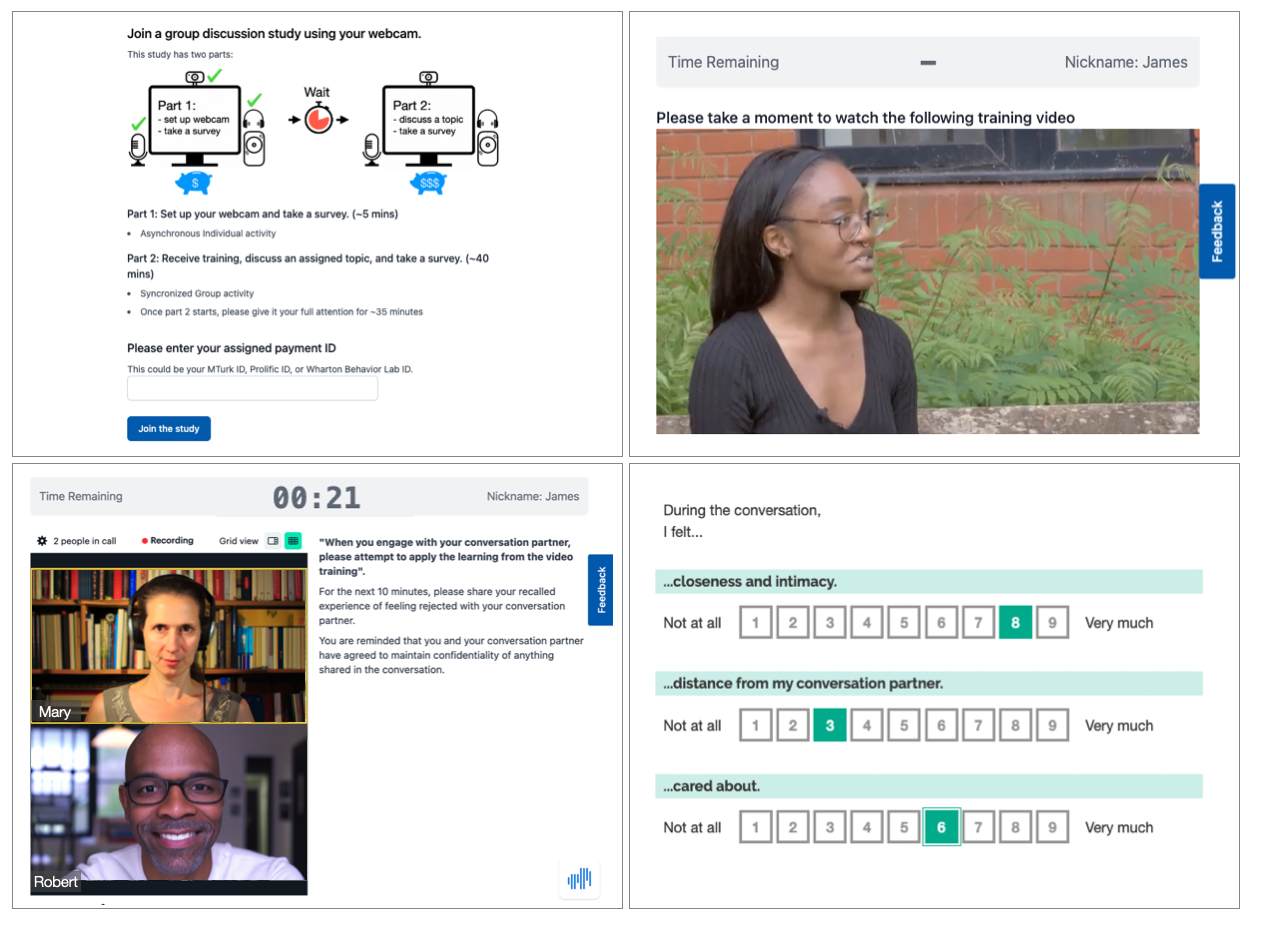
The core technology developed to support this project is an online laboratory for conducting small-group deliberation experiments at scale. The virtual laboratory handles much of the overhead work that would normally require human facilitation, for example:
- Recruiting participants and recording consent
- Measuring baseline characteristics such as sociodemographic or psychometric attributes that can be used to characterize the participants in a given discussion
- Assigning participants to groups to create a desired demographic composition within each group
- Delivering interventions
- Coordinating one or more video-call discussions between participants
- Conducting post-discussion surveys
By removing the need for human facilitators, we can dramatically increase the number of deliberation exercises that a research team can include in a given study.
Space-aware models
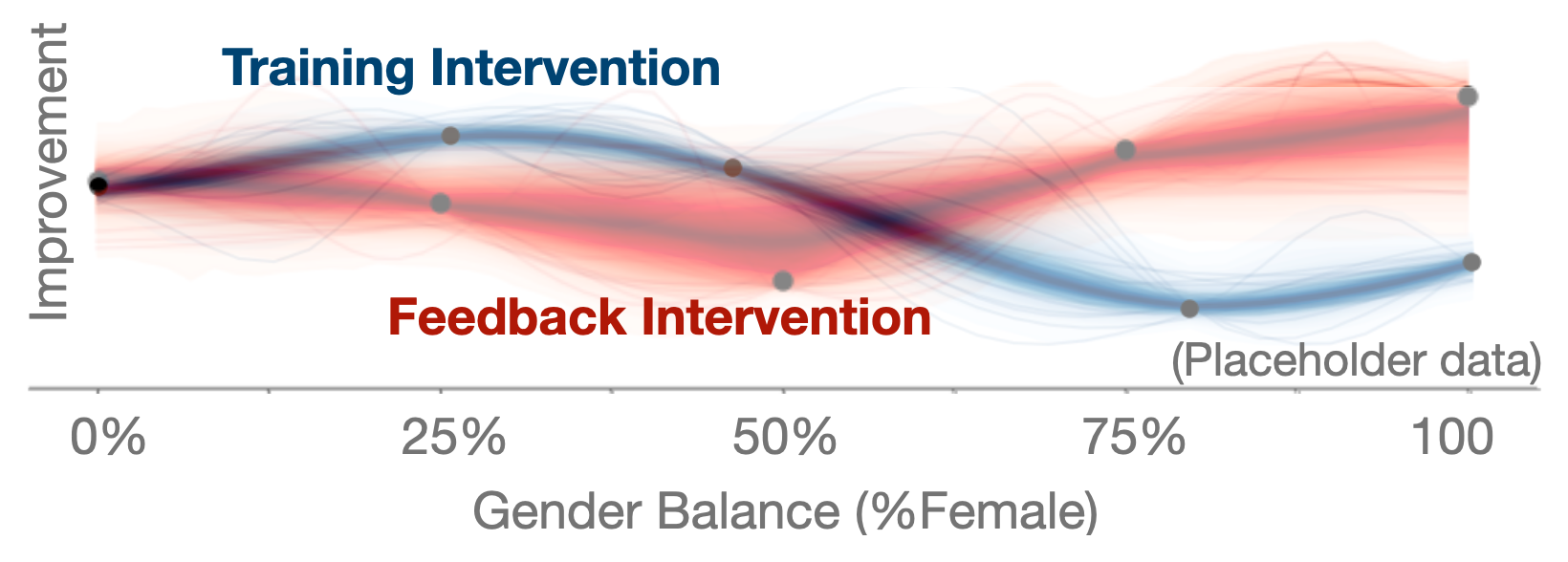
As we can never truly cover the full parameter space with experiments, we need a way to use the information we have to make predictions about points in the space we have yet to sample. These models can take a number of forms, subject to the constraint that they weigh information from nearby points in the design space more heavily than from distant points. This allows us to split the difference between overgeneralizing from about the space as a whole and overfitting to local results.
Open-science practices
The Deliberation Lab is also pioneering a number of different open science practices aimed to improve the visibility, traceability and replicability of the experimentation process.
Composable experiments
Experiments conducted in the Deliberation Lab specify their conditions using a standard format. This “experiment manifest” includes information about the number of people assigned to a group, how they are assigned to roles in the discussion, and the timing and layout of visual and interactive elements within the stages they progress through in the study.
This manifest is automatically interpreted by the virtual laboratory to conduct the experiment as specified, and provides a straightforward way to preregister each experiment trial. The manifest is saved with the data object that results from the sample, allowing researchers to precisely document the experiment procedure, and perform exact replications in a straightforward manner.
The following example illustrates an experiment condition in which two people have a 10-minute discussion about their views on urban rioting. One is randomly assigned to present their views on the topic, while the other is told to listen. Their attitudes are measured before and after the discussion, and they are then given standardized surveys measuring their percption of their alter’s listening behavior.
- name: baseline_control
desc: Listening study baseline condition
playerCount: 2
assignPositionsBy: random
gameStages:
- name: Intro
type: prompt
duration: 45
elements:
- intro_no_training.md
- type: submitButton
- name: Attitude Presurvey
duration: 120
elements:
- urban_unrest_survey.md
- type: submitButton
- name: Discussion
duration: 600
chatType: video
elements:
- type: prompt
file: urban_unrest_discussion.md
- type: prompt
file: instructions_listener.md
showToPositions:
- 0
- type: prompt
file: projects/weinstein_listening/instructions_speaker.md
showToPositions:
- 1
- name: Attitude Postsurvey
duration: 120
elements:
- projects/SDC_behavior/urban_unrest_survey.md
- type: submitButton
exitSurveys:
- ConstructiveListeningBehaviors
- Demographics
Instant pre-registration
As the virtual lab automates the running of experiments, we are able to preregister each sample as it begins. This allows for full traceability of data collection through to actual published data. While allowing for temporary embargo of data prior to publication, this traceability helps avoid the “file drawer” problem by providing an easy way to measure the data publication rate, and coordinate the release of embargoed data.
Out-of-sample prediction
Rather than relying on out-of-date statistical procedures, the virtual lab is set up to measure the credibility of its data and models using best practices taken from the field of machine learning. Different models are adjudicated based on their ability to make predictions for data that was not present in the training dataset. By comparing the predictive accuracy of formal theoretical models with that of unconstrained ML models, we can get an estimate of the amount of predictable variance explained by current theory, and determine areas in which efforts to expand existing formal theory might be most fruitful.
Continuous experimentation
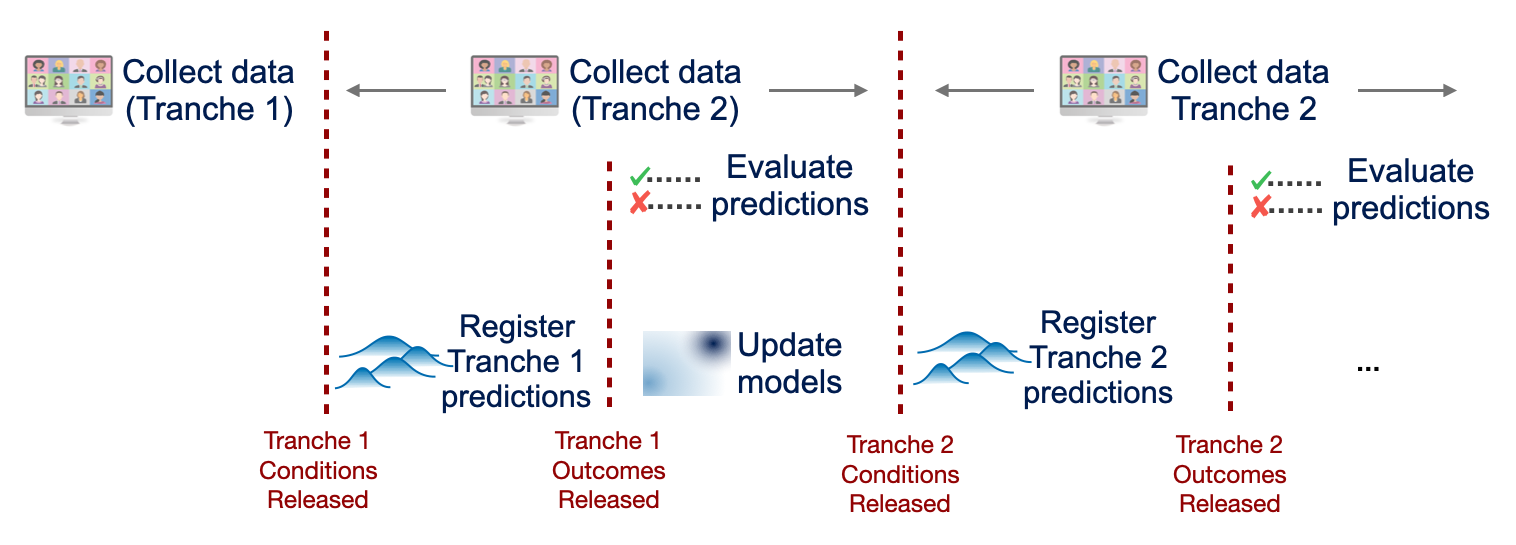
Combining automated experimentation with out-of-sample prediction enables a new workflow for conducting experiments. In a traditional experimental paradigm, all data collection and statistical analyses are preregistered before collecting data in a single campaign. The tools we are developing allow us to move towards continuous data collection, such that the credibility of models trained on data collected up to this week is assessed on its ability to predict data taken next week.
Infrastructure
The Deliberation Lab is built on top of two external tools for orchestrating multiplayer real-time experiments and supporting video-based communication between participants.
Multiplayer experiments: Empirica
Our platform uses Empirica, an open-source web framework for running real-time multiplayer experiments in the browser. In the Deliberation Lab, Empirica manages coordination between participants’ web browsers and our central server, ensuring that everyone in a given group remains synchronized with one another and with the server as they progress through various stages.
Empirica helps assign players to groups, delivers the appropriate stimuli to the right participants at the right time, and facilitates data collection. This infrastructure allows us to run tightly synchronized, multi-participant experiments without needing manage low-level real-time coordination of participants computers.
Video communication: Daily.co
To enable video-based discussions, we integrate Daily.co, a third-party provider of WebRTC-based video services. Daily provides low-latency video connections for participants and manages the recording and secure transmission of video data to our servers.
Future directions
The tools described here are under active development and test. The diagram below identifies the major technical components of the virtual lab architecture and their state of development.
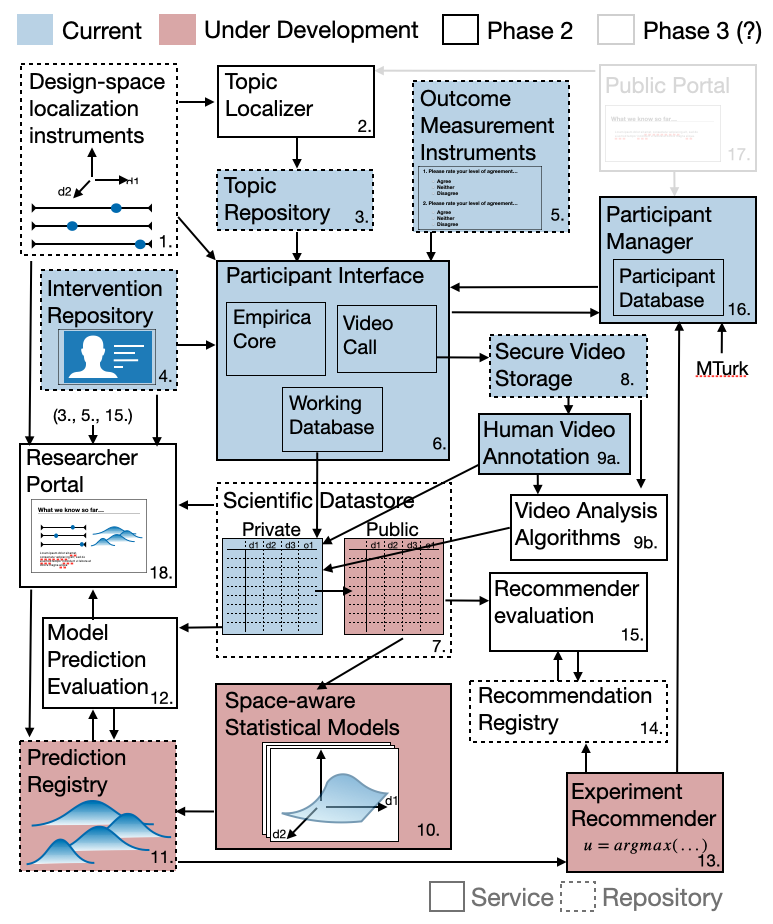
Also under development are interventions that monitor a discussion and use live feedback to help participants share time and surface opinions of less active members. The first of these will be a visual dial to show the amount of time teh participant has spent talking, encouraging equitable participation and discouraging dominance by certain individuals. Follow-on interventions may include reflections of sentiment or other behaviors.
Also under development are tools that allow participants to collaborate on a shared work product, such as a canvas for co-writing a group response to a particular discussion topic.